
No items found.
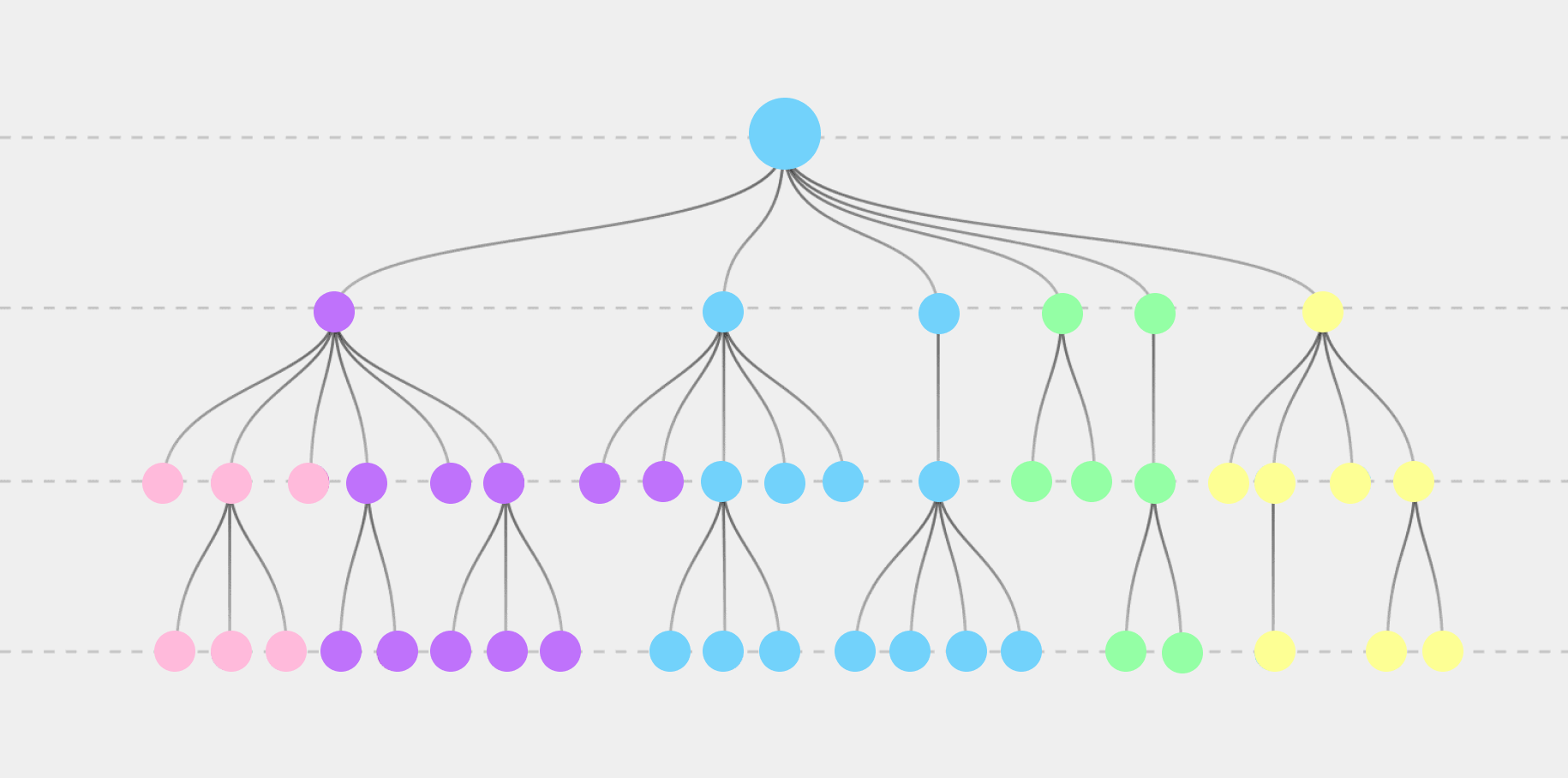
Decision trees have been used in various areas from customer service to machine learning. Let's talk about what problems this method solves in data analysis and how to build a decision tree.
Decision Tree
A decision tree is one of the machine learning algorithms. The algorithm is based on the rule: "If <condition>, then <expected result>".
Example: if the subscriber pressed the number "1" after the voice greeting, then the call must be transferred to the sales department.
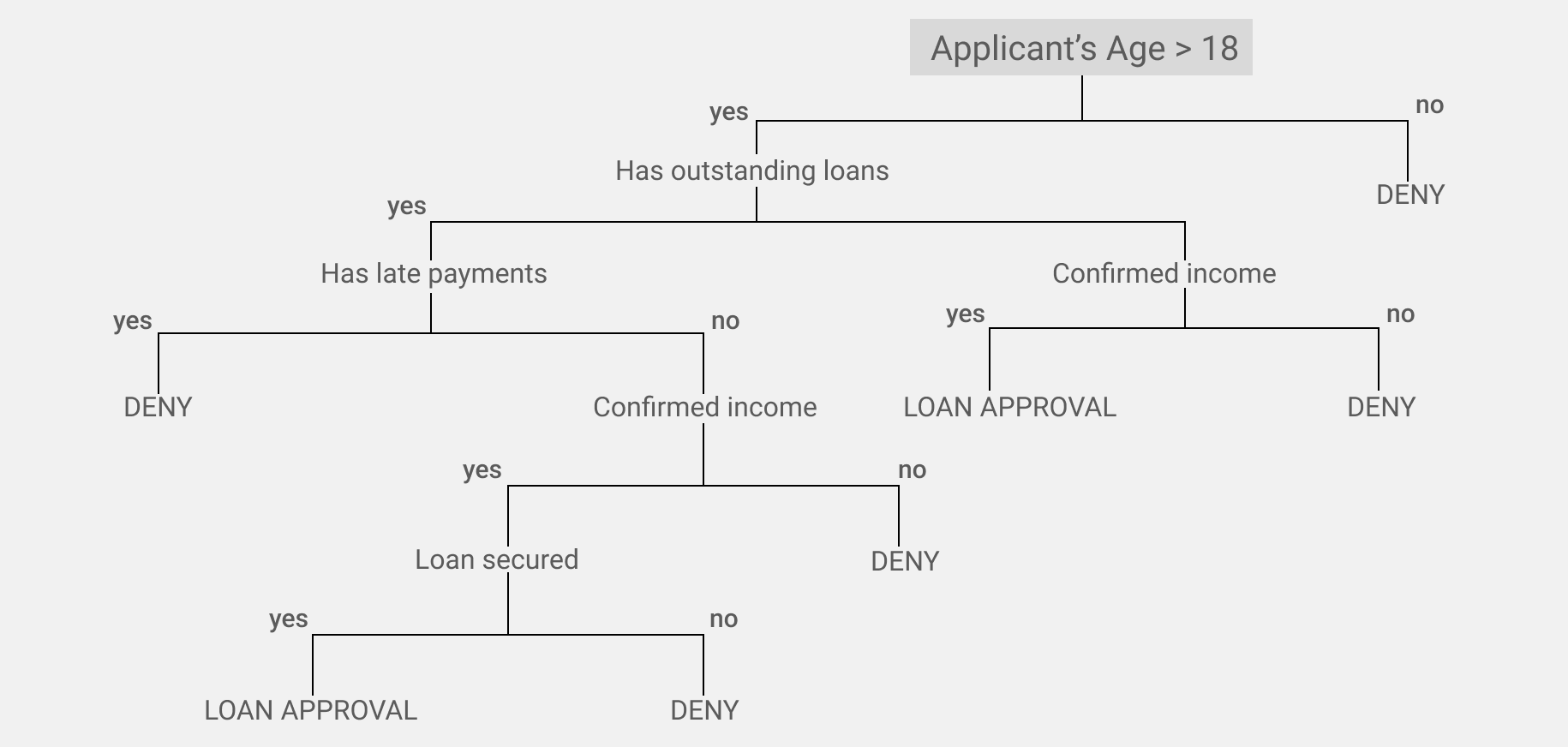
Decision trees are often used in the banking sector and in those areas where scripts are used to communicate with customers and decision-making processes need to be managed. An example of such an area is financial services, where banks and insurance companies check customer information in a strict sequence to assess risks before entering into a contract.
Structure
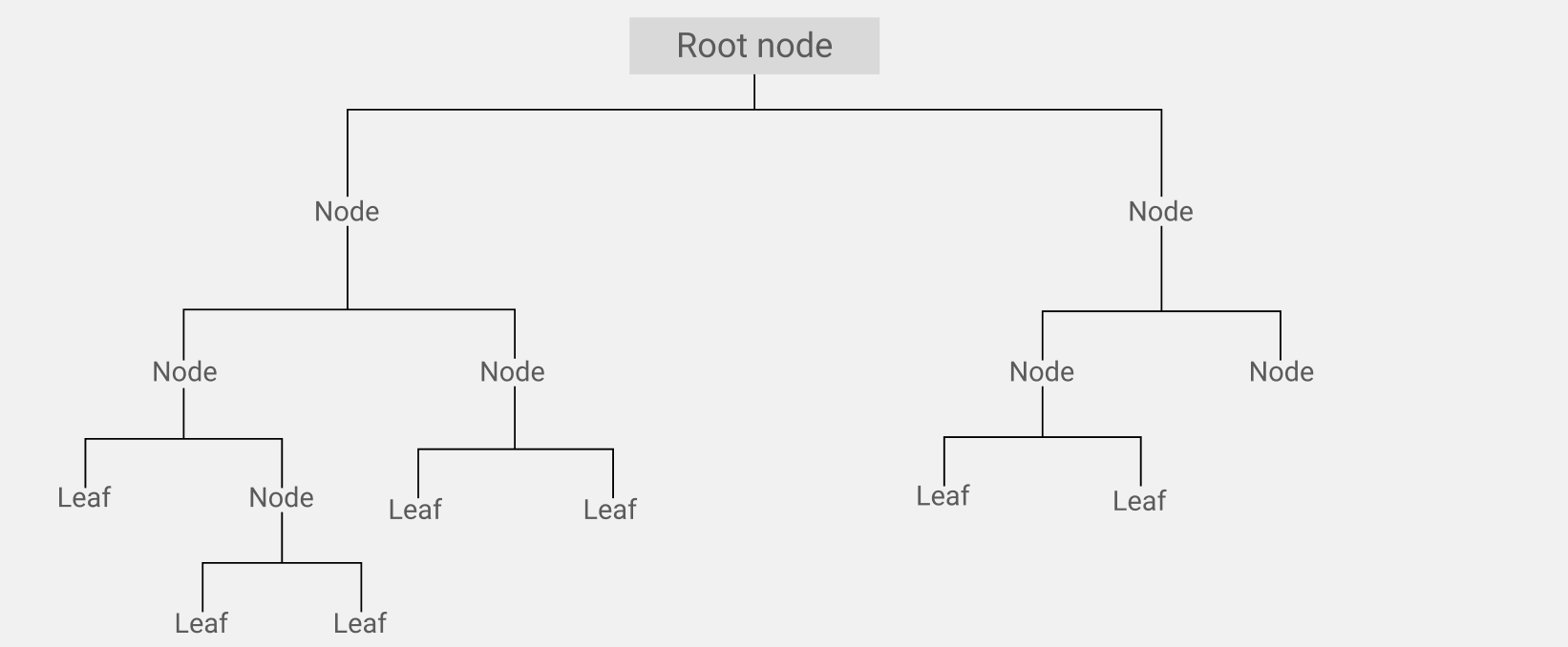
A decision tree consists of "nodes" and "leaves". At the top of the tree is the initial root node into which the entire selection falls. Next, there is a check for the fulfillment of a condition or the presence of a sign. As a result of such a check, the data group is divided into subgroups: a subgroup of data that passed the test, and a subgroup of data that do not meet the specified condition.
Further, subgroups of data fall into the next node with a new check. And so on to the final node of the task tree, which meets the given goal of data analysis or completes the decision-making process.
When to Apply It?
In its “pure” form, the decision tree algorithm was used to generate scripts for communicating with customers in banks, insurance companies, sales, and customer service.
Example: the user did not complete the card payment through the bank application, he writes to the support service chat. The bank employee who answers the request will follow the algorithm: for example, the first thing he will ask is the payment ID. Further, the decision tree will branch depending on whether the user knows the identifier or not.
Scripts for the sales department are also most often based on the decision tree model: managers ask questions to a potential client and, depending on the answer, adjust the next question.

In machine learning, statistics, and data analysis, you can use the decision tree method to make predictions, describe data, divide it into groups, and find relationships between them.
A simple and popular problem is binary classification. That is, the division of a set of elements into two groups, where, for example:
- 1 - success, yes, the answer is correct, the user repaid the loan;
- 0 - failure, no, the answer is incorrect, the user did not return the loan.
Another example, based on meteorological observations for the past 100 days, you need to make a forecast whether it will rain tomorrow. To do this, you can divide all days into two groups, where:
- 1 - the next day it was raining;
- 0 - no rain the next day.
You can analyze a set of characteristics of each day: average temperature, humidity, whether it has rained in the past two weeks. The decision tree algorithm will search the total amount of data for those repeated conditions by which it is easiest to divide all days into “1” and “0”. Such conditions increase the likelihood of the desired result.
What Tasks Does the Method Solve?
In machine learning and data analytics, a decision tree is used to:
- Classify data.
With the help of a decision tree, we can examine the characteristics of different cases or objects and, based on the results, divide them into categories and subcategories. - Determine the most significant conditions.
The decision tree algorithm helps to evaluate the importance of a feature. That is, to find such conditions that are most important for the given purpose of the study. Such conditions are closest to the beginning of the division of the main sample. If you build 100 trees to solve the same problem, then, most likely, at the beginning of these trees there will be the same conditions. - Increase the reliability of the result.
A decision tree helps to form the most suitable sample for all conditions or make the most accurate forecast based on the available data.
Advantages and Disadvantages
Advantages:
- Simplicity.
Each division follows one attribute, so you can easily interpret the results and quickly find the conditions that influenced them the most. For example, why a bank employee refused a loan to an applicant? Because of age, lack of documents confirming income, or past due payments on past loans.
Disadvantages:
- Limited use.
The simplicity of the method is both an advantage and a disadvantage. Because of this, the use of the decision tree is limited. The algorithm is not suitable for solving problems with more complex dependencies. - Tendency to overlearn.
The decision tree model adjusts to the data it receives and looks for features that increase the likelihood. The tree creates subgroups of elements until the final subgroup becomes homogeneous in all respects or gives a perfect prediction. Because of this, the algorithm will not be able to make a prediction for characteristics that were not in the training sample.
Linear models can make predictions for values that were not in the sample, but decision trees cannot, since this method is based on averaging values.
How to Build a Decision Tree?
In data analysis and machine learning, a decision tree does not need to be manually created. Analysts use special libraries for this, which are available in two programming languages: R and Python.
Within Python, for example, there is a free scikit-learn library of standard machine learning models that provides a Decision Tree class with pre-cooked code.
Main Steps
Before building a decision tree using pre-built code, it's required to:
- Collect data and do exploratory analysis.
First, experts analyze the data and look for common patterns and anomalies. Then they form a hypothesis about the format of the model - why the decision tree is suitable for the task. At this stage, hypotheses are also built about the influence of factors on the dependent variable and the data pre-preparation pipeline. - Conduct pre-training.
The data is brought to the desired format and cleaned of anomalies. There are special algorithms and approaches for data preprocessing such as filling gaps with mean, median values, normalization of indicators relative to each other, removal of anomalies if necessary, and categorization of variables. - Form a deferred sample.
A small part of all the data needs to be set aside, analyzed independently and determine the main value for the final result. This is done so that after training the decision tree model, you can compare the results and check the quality of the algorithm on observations that the trained model has not seen before. - Build a decision tree and run model training.
At this stage, the library is loaded with data or the part that remains after the formation of the delayed sample, and the conditions of the problem. “If…then…” rules are generated automatically during model training. - Compare the results on the training sample and on the deferred one.
If the results are comparable and the deferred sample is formed correctly, then the model algorithm is working correctly. The analyst then saves the code of the trained model and uses it to make decisions and create predictions based on the new data.


